




Horizontal AI Infra & "Why Now"

Introduction
The evergreen investment questions are “why them” and “why now.”
So much has been written about founder experience and defensibility in AI– and I won’t add to that here.
However, I wanted to share some thoughts on market timing and maturity.
We’ve seen the “why now” for AI move broadly up and down what we now understand is the AI stack.
Right after ChatGPT launched, we saw most startups race to build horizontal infrastructure that could be used across any industry and application. This made sense— the OpenAI API is insanely powerful, and more was needed to leverage LLMs. But this excitement was met with a lot of struggle to gain traction since the market was moving so quickly. Everyone was still figuring it out on their own and unwilling to buy someone else’s solution.
Next, there was a notable shift to vertical applications — as startups targeted direct customer needs and workflows within specific industries. These applications aimed to automate workflows, create knowledge management tools and add built-in search and chat. Some recognizable examples are Harvey for Law, Lemonade for Insurance, and Abridge for Healthcare.
With “why now,” we often think of the decade-long trends that define an era (e.g. mobile, cloud). But there are also shorter, more targeted windows of time when a company can get the momentum it needs to reach the next milestone, and scale. I believe we’ve hit a moment where the challenges of scaling and integrating LLMs are well-defined, the industry has matured, and there are opportunities for early-stage startups that are building horizontal solutions to gain adoption.
Natalie and I have been asking ourselves: what are the biggest horizontal infrastructure opportunities? I wanted to share some of our high-level thoughts and research on RAG, routers, and real-time content moderation.
RAG
If you’ve used any AI application in the past two years, chances are that it’s used RAG under the hood. It’s become a critical part of the stack.
RAG is a method that combines pre-trained LLMs with a retrieval-based framework to enhance accuracy, personalization, and contextual relevance in text generation. RAG has gained traction because it allows LLMs to tap into specialized knowledge databases.
Let’s say you want to ask a question: Can you tell me the last five companies I spoke to and summarize each company’s meeting notes into two bullet points?
The application will be able to answer the question correctly because it uses RAG methods to access and retrieve your company’s data.
This is a massive market to capture, and a number of players are building products within it. Companies delivering RAG solutions loosely fall into the following categories:
RAG-as-a-service focused startups: Ragie, Nuclia, SciPhi, WhyHow, Vectara, Superlinked, Ryddle AI
Unstructured ETL: Unstructured IO
Vector databases: Weaviate, Pinecone, Chroma, Quadrant, LanceDB
Applications that are comprehensive AI and data solutions: Datastax, Haystack, Hebbia, Cohere, Contextual AI
Dealing with different datasets, data privacy, data access, and maintaining accuracy across multimodal data — is difficult. Many of the current solutions are limited to ‘standard-RAG’, only connecting third-party data and not actually addressing the challenges and demands of operating at scale. We see a big opportunity for a startup to win this space as RAG complexity increases.
Related – we recently made an investment in a RAG company. Look out for the official announcement and more information soon!!
LLM Routers
LLM routers connect prompts to different models to provide the best output for the given task.
Routers distinguish between simple questions that can be handled by less powerful models and complex questions that require more sophisticated processing.
For example, if you’re asking, “What is a recipe for stir-fry?” you don’t need a fancy model. In contrast, a question like: “Can you please provide a comprehensive analysis of recent regulatory changes that have impacted (positively or negatively) crypto/web3 over the past five years? Please include dates, key metrics, market dynamics, and legal implications” requires something more advanced.
The complexity of the second question lies in its:
Depth and time horizon - analyzing over a 5-year period.
Data retrieval - accessing up-to-date information from different sources.
Precision - providing specific dates and key metrics.
Contextual relevance - ensuring information relates directly to web3/crypto.
Computation - generating a detailed response.
RAG implementation - utilizing RAG for current and precise data.
Researchers at UC Berkeley recently released a paper introducing a router framework they created called RouteLLM and analyzing current routers – RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing”. The results of the performance are visualized in the graph below.
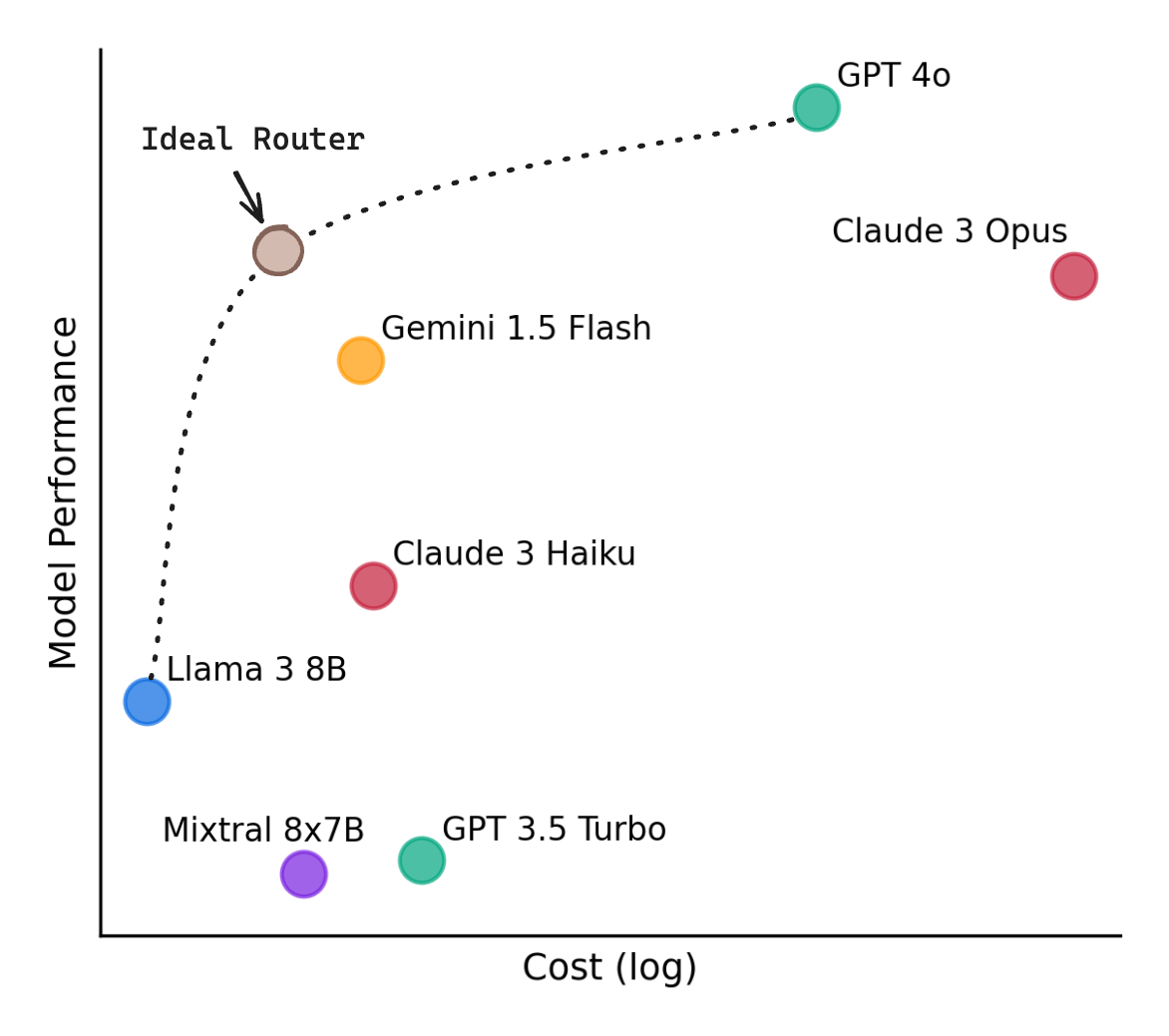
By connecting prompts to different models with the best output, researchers showed that they can reduce the cost of using LLMs by over 40% while maintaining performance as high as GPT-4o.
Examples of companies building in this space are: Substrate, AnyScale, Martian, and Unify.
The importance of routers will continue to grow. From an investing perspective, the key question is whether it is a “race to the bottom” since foundational models are competing for market share and incentivized to keep the price per API call low. That dynamic may make it difficult for LLM router startups to capture significant revenue because the calls themselves are already so cheap. OR are the value propositions in performance, cost, data privacy, scale, and ease of use enough to lead to a big outcome in a routing company?
Real-Time Content Moderation
Over the past decade, we’ve seen a shift in philosophy and growing recognition of the importance of content integrity. The classic example: Facebook’s “move fast and break things” clashed with the growing need for digital safety and accountability as the platform matured.
Now, as the vast majority of content becomes auto-generated through prompts and responses, content detection and online safety are more important than ever.
If you’re Disney and live-streaming a character? That character can’t produce any sexualized responses or use offensive language.
Or an educational platform? It would be a massive reputational risk if teenagers could prompt themselves into generating harmful content.
How about voice infrastructure? Is there a business risk of someone using your product to clone a political figure?
Or code generation: you can’t have co-pilots auto-generating malicious code.
Detection and moderation solutions depend on real-time monitoring and understanding of the model’s outputs. It’s a messy and hard problem, but it is business-critical.
Where the market is heading — I’m interested to see whether OpenAI or any of the other foundational model companies will build safeguards. They are in the best position to offer solutions, but historically, companies in their position have been hands-off in defining policy and preventing the misuse of the product.
Some startups building in this space are: Hugging Face has detection models, Haize Labs, Unitary, and Checkstep.
Outro
Thank you for reading! If you’re a founder building in any of these spaces, or an investor/engineer thinking about similar things – I’d love to connect!
I’m an investor at Chapter One, an early-stage venture fund that invests $500K —$1.5M in innovative pre-seed and seed-stage startups.
You can find me on LinkedIn (Jamesin Seidel) or Twitter (@seidtweets).



